- RDS Custom for SQL Server now supports Local Time Zones
- Amazon RDS for SQL Server supports minor version 2019 CU21
- Amazon RDS for SQL Server now supports self-managed Active Directory
- Amazon RDS for SQL Server supporAmazon RDS for SQL Server now supports SQL Server 2016 SP3, 2017 CU27, and 2019 CU15ts minor versions 2014 GDR, 2016 GDR, 2017 CU31 GDR, and 2019 CU20
- RDS Custom for SQL Server lets you Bring Your Own Media
- RDS Custom for SQL Server now supports Multi-AZ deployments
- Amazon RDS for SQL Server now supports Cross Region Automated Backups with encryption
- Database Activity Streams now supports Amazon RDS for SQL Server
- Amazon RDS for SQL Server now supports email subscription for SQL Server Reporting Services (SSRS)
- Amazon RDS Proxy now supports Amazon RDS for SQL Server
- Amazon RDS for SQL Server Now Supports TDE enabled SQL Server Database Migration
- Amazon RDS for SQL Server now supports SQL Server 2014 SP3 CU4 SU
- Amazon RDS for SQL Server now supports SQL Server 2016 SP3, 2017 CU27, and 2019 CU15
- Amazon RDS for SQL Server now supports SSAS Multidimensional
- Amazon RDS for SQL Server now supports new minor versions for SQL Server 2019 and 2017
- Amazon RDS for SQL Server now supports Always On Availability Groups for Standard Edition 2017
- Amazon RDS for SQL Server now supports M6i and R6i instances
- Amazon RDS for SQL Server now supports SQL Server Agent job replication
- Amazon RDS Custom for SQL Server now supports Custom Engine Version to improve resiliency of customizations
- Amazon RDS Custom for SQL Server now supports AWS CloudFormation Templates
- Amazon RDS for SQL Server now supports Cross Region Read Replica
- Amazon RDS for SQL Server now supports a linked server to Oracle
- Amazon RDS for SQL Server Now Supports Access to Transaction Log Backups
- Amazon RDS Proxy now supports Amazon RDS for SQL Server
- Amazon RDS Custom for SQL Server now supports scaling storage
- Amazon RDS for SQL Server supports M6i, R6i and R5b instances in additional regions
- Amazon RDS for SQL Server now supports email subscription for SQL Server Reporting Services (SSRS)
- Amazon RDS for SQL Server now supports secondary host metrics in Enhanced Monitoring
- Amazon RDS for SQL Server now supports self-managed Active Directory
Tuesday, 8 August 2023
AWS RDS SQL Server Announcements - 2022 & 2023
Wednesday, 31 May 2023
Microsoft Announcement: Microsoft Fabric
Yesterday at Microsoft Build, a significant announcement took place—the introduction of Microsoft Fabric, which is now available for public preview. Satya Nadella, the CEO of Microsoft, went as far as describing Microsoft Fabric as "The biggest launch of a Microsoft data product since the launch of SQL Server." In this blog post, I will provide an introduction to Microsoft Fabric and component involved.
To truly grasp the concept of Microsoft Fabric, envision it as an extension of Power BI that integrates SaaS versions of various Microsoft analytical products into the Power BI workspace, now referred to as a Fabric workspace.
Microsoft Fabric
Microsoft Fabric is an integrated analytics solution designed for enterprises. It encompasses various aspects of analytics, including data movement, data science, real-time analytics, and business intelligence. The platform offers a comprehensive set of services, such as data lake, data engineering, and data integration, all in one place. Unlike using multiple services from different vendors, Fabric provides a highly integrated and user-friendly product that simplifies analytics requirements. It is built on a Software as a Service (SaaS) foundation, which enhances simplicity and integration.

Microsoft Fabric is an integrated environment that combines components from Power BI, Azure Synapse, and Azure Data Explorer into a unified platform. It offers customized user experiences and brings together various functionalities like Data Engineering, Data Factory, Data Science, Data Warehouse, Real-Time Analytics, and Power BI.
The integration of these components on a shared Software as a Service (SaaS) foundation brings several benefits. It provides a wide range of deeply integrated analytics capabilities, offering a comprehensive solution for industry needs. Users can leverage shared experiences that are familiar and easy to learn, promoting efficiency and collaboration.
Developers can access and reuse assets easily, enhancing productivity and enabling faster development cycles. The platform allows for a unified data lake, enabling data to be stored in its original location while utilizing preferred analytics tools. This centralizes administration and governance across all experiences, simplifying management tasks.
The Microsoft Fabric SaaS experience seamlessly integrates data and services, eliminating the need for users to handle or understand the underlying infrastructure. Core enterprise capabilities can be centrally configured, and permissions are automatically applied across all services. Data sensitivity labels are also inherited across the suite.
Microsoft Fabric is a comprehensive analytics platform that offers a range of experiences designed to seamlessly work together. Each experience is tailored to a specific task and user persona, covering various aspects of analytics. Here are the key experiences provided by Fabric:
1. Data Engineering: This experience offers a powerful Spark platform for data engineers to perform large-scale data transformations and democratize data through the lakehouse. It integrates with Data Factory for scheduling and orchestration.
2. Data Factory: Azure Data Factory combines the simplicity of Power Query with the scalability of Azure Data Factory. It provides over 200 connectors to connect to on-premises and cloud data sources.
3. Data Science: The Data Science experience allows building, deploying, and operationalizing machine learning models within Fabric. It integrates with Azure Machine Learning for experiment tracking and model registry, enabling data scientists to enrich organizational data with predictions.
4. Data Warehouse: Fabric's Data Warehouse experience offers industry-leading SQL performance and scalability. It separates compute and storage, allowing independent scaling of both components. It also supports the open Delta Lake format.
5. Real-Time Analytics: This experience is designed for analyzing observational data collected from various sources like apps, IoT devices, and human interactions. It excels in handling semi-structured data with shifting schemas.
6. Power BI: Power BI is a leading Business Intelligence platform that allows business owners to access and analyze data from Fabric quickly and intuitively, enabling better decision-making.
By bringing together these experiences into a unified platform, Microsoft Fabric offers a comprehensive big data analytics solution. It enables organizations and individuals to leverage large and complex data repositories for actionable insights and analytics. Additionally, Fabric implements the data mesh architecture, which focuses on decentralized data ownership and domain-driven data products.
OneLake is a unified and logical data lake provided within Microsoft Fabric. Similar to how OneDrive serves as a central storage solution for individual users, OneLake serves as a centralized repository for analytics data within an organization. It is automatically available for every Microsoft Fabric tenant and is designed to be the single location for storing and managing all analytics data. With OneLake, organizations can benefit from having one data lake that caters to the entire organization's analytics needs, promoting data consistency, accessibility, and collaboration.
In the context of a SaaS service like Microsoft Fabric, a "tenant" refers to a customer's organization or account. The concept of a tenant provides unique benefits, including clear boundaries for governance and compliance, which are controlled by the tenant admin. By default, any data that is stored in OneLake, the unified data lake within Fabric, is governed within the boundaries set by the tenant admin.
While the tenant admin has control over the governance and compliance aspects, it is important to avoid the admin becoming a central gatekeeper that hinders contributions from other parts of the organization. Within a tenant, multiple workspaces can be created, enabling different parts of the organization to distribute ownership and access policies. This allows for decentralized management and ensures that various teams or departments can contribute to OneLake without relying solely on the admin.
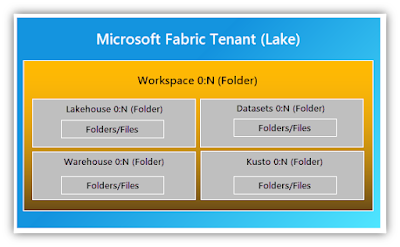
Each workspace is associated with a specific region and has its own capacity, which is billed separately. This allows for granular control and cost management within the organization. By creating workspaces, organizations can effectively distribute ownership and access policies, promoting collaboration while maintaining proper governance and compliance within the boundaries defined by the tenant admin.
In a Microsoft Fabric workspace, data is organized and accessed through data items. These items serve as containers for different types of data within OneLake, similar to how Office files like Word, Excel, and PowerPoint are stored in OneDrive. Fabric supports various types of data items, including lakehouses, warehouses, and other related components.
The use of data items allows for tailored experiences based on the specific needs and roles of different personas within the organization. For example, a Spark developer may have a dedicated data item for their lakehouse, providing them with a customized experience for their data transformation and analysis tasks.
To get started with OneLake and create a lakehouse, you can refer to the documentation on "Creating a lakehouse with OneLake." This resource will provide guidance on setting up and utilizing OneLake within Microsoft Fabric, allowing you to leverage the benefits of a unified data lake and tailored experiences for different personas.
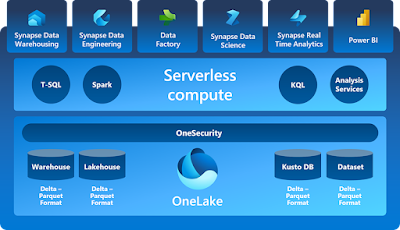
OneLake
OneLake, built on Azure Data Lake Storage Gen2, provides open support for various file types, whether structured or unstructured. All data items within Microsoft Fabric, such as data warehouses and lakehouses, automatically store their data in OneLake using the delta parquet format. This means that regardless of whether a data engineer loads data into a lakehouse using Spark or a SQL developer loads data into a fully transactional data warehouse using T-SQL, all contributions contribute to building the same data lake.
Tabular data is stored in OneLake using the delta parquet format, ensuring efficient storage and retrieval. OneLake supports the same Azure Data Lake Storage Gen2 APIs and SDKs, making it compatible with existing applications that utilize ADLS Gen2, including Azure Databricks. This allows for seamless integration and compatibility with existing workflows and tools.
Data within OneLake can be addressed as if it were a single, large ADLS storage account for the entire organization. Each workspace within Fabric appears as a container within that storage account, and different data items are organized as folders within those containers. This logical organization makes it easier to navigate and manage data within OneLake while leveraging the capabilities and compatibility of Azure Data Lake Storage Gen2.
The OneLake file explorer allows users to interact with their data lakes directly from their Windows machines, providing a convenient and intuitive interface. Users can explore and manage their data items within workspaces, perform file operations, and leverage familiar features just like they would with Office files in OneDrive.
By offering a file explorer-like experience, OneLake brings the power of data lakes to the hands of business users, eliminating the need for specialized technical knowledge. This enables a broader range of users to effectively work with and derive insights from the data stored in OneLake.
The goal of OneLake is to enable users to leverage the full value of their data without the overhead of duplicating or transferring it. This approach promotes efficiency, reduces complexity, and facilitates better collaboration and analysis by breaking down data silos and enabling data to be analyzed in its original location.
In summary, OneLake eliminates the need for data duplication and movement, ensuring that organizations can derive maximum value from their data without unnecessary complexity or data silos.
Overall, Fabric empowers creators to focus on their work without worrying about integrating or managing the underlying infrastructure, fostering productivity and enabling a streamlined analytics experience.
Thursday, 16 June 2022
Migrate Amazon RDS for SQL Server to Azure SQL Managed Instance.
Applications are closely dependent on the databases and application evolution is frequently connected with an upgrade of the application database. Database migration is process of moving customer’s database from a source instance to a destination instance. This process includes not only the move from one instance to another, but also a modernization process - from one version of SQL Server to a newer one (or from a legacy & unsupported to a supported one).
There are multiple ways to migrate databases hosted in Amazon Relational Database Service (Amazon RDS) for SQL Server to Azure SQL Managed Instance. For use cases such as migrating from Amazon Elastic Compute Cloud (Amazon EC2) to SQL Server on Azure SQL Managed Instance, you can use a number of ways and tools, including Database Migration Assistant (DMA) Link feature for SQL Managed Instance or Log Replay Service. When it comes to migrating RDS for SQL databases, we cannot use DMA or Log Replay Service methods because RDS SQL Server takes backups without checksum enabled and both of these methods require backups to have the checksum enabled in order to verify the consistency at the restore time.
This is the Multi blog post series on the Amazon RDS for SQL Server to Azure SQL Managed Instance migration that will serve as an introduction and an overview of the series.
In the later posts of these series, we compare different migration methods to help you to understand the features, benefits, nature of complexity, trade-off's involved in each of them.
📌 Links to bookmark: 📌
Part 1 - Migrate Amazon RDS for SQL Server to Azure SQL Managed Instance – Part 1 (Overview)
Part 2 - Migrate Amazon RDS for SQL Server to Azure SQL Managed Instance – Part 2 (Native Backup & Restore)
Part 3 - Migrate Amazon RDS for SQL Server to Azure SQL Managed Instance – Part 3 (Azure Data Factory)
Monday, 15 November 2021
Architect a Managed Disaster Recovery on Amazon RDS for SQL Server
Customers often ask for guidance on choosing the right DR solution for RDS SQL Server. In this blog series, we cover the DR solutions available for Amazon RDS for SQL Server. If you're looking for advice on best practices,trade-offs, operational costs & complexity, time to recovery... then this is it!
📌 Links to bookmark: 📌
Part 1 - https://aws.amazon.com/blogs/database/part-1-architect-a-managed-disaster-recovery-on-amazon-rds-for-sql-server/
Part 2 - https://aws.amazon.com/blogs/database/part-2-architect-a-managed-disaster-recovery-on-amazon-rds-for-sql-server/
AWS RDS SQL Server Announcements - 2021
AWS RDS SQL Server Announcements - 2021
- https://aws.amazon.com/about-aws/whats-new/2021/01/amazon-rds-for-sql-server-now-supports-tempdb-on-local-instance-store-with-r5d-and-m5d-instance-types/
- https://aws.amazon.com/about-aws/whats-new/2021/02/amazon-rds-for-sql-server-now-supports-always-on-availability-groups-for-standard-edition/
- https://aws.amazon.com/about-aws/whats-new/2021/04/amazon-rds-sql-server-supports-extended-events/
- https://aws.amazon.com/about-aws/whats-new/2021/05/amazon-rds-for-sql-server-supports-managed-disaster-recovery-with-amazon-rds-cross-region-automated-backups/
- https://aws.amazon.com/about-aws/whats-new/2021/05/announcing-amazon-rds-for-sql-server-on-aws-outposts/
- https://aws.amazon.com/about-aws/whats-new/2021/07/amazon-rds-sql-server-supports-new-minor-versions/
- https://aws.amazon.com/about-aws/whats-new/2021/09/amazon-rds-sql-server-msdtc-jdbc-xa-sql-server-2017-cu16-plus-sql-server-2019/
- https://aws.amazon.com/about-aws/whats-new/2021/09/amazon-rds-sql-server-msdtc-jdbc-xa-sql-server-2017-cu16-plus-sql-server-2019/
Tuesday, 3 August 2021
Architect a disaster recovery for SQL Server on AWS: Part 1
New blog post - Architect a disaster recovery for SQL Server on AWS
Customers often ask for guidance on choosing the right HA or DR solution for SQL Server on AWS. 🤔
In this blog series, there is now a helpful and concise guide into various architectural
best practices available. If you're looking for advice on trade-offs,
operational costs & complexity, time to recovery... then this is it!
🔥
Topics include; backup and restore, SQL Server log shipping,
SQL Server database mirroring, SQL Server Always on Failover Cluster
Instances (FCIs), Always On availability groups, AWS Database Migration
Service (AWS DMS) & CloudEndure Disaster Recovery.
📌 Links to bookmark: 📌
Part 1 - https://aws.amazon.com/blogs/database/part-1-architect-a-disaster-recovery-for-sql-server-on-aws/
Part 2 - https://aws.amazon.com/blogs/database/part-2-architect-a-disaster-recovery-for-sql-server-on-aws/
Part 3 - https://aws.amazon.com/blogs/database/part-3-architect-a-disaster-recovery-for-sql-server-on-aws/
Part 4 - https://aws.amazon.com/blogs/database/part-4-architect-a-disaster-recovery-for-sql-server-on-aws/
Now go build! 💥🚀
Seamlessly migrate large SQL databases using AWS Snowball and AWS DataSync.
New blog post - Seamlessly migrate large SQL databases using AWS Snowball and AWS DataSync.
In this blog post, I covered how to simplify large SQL Server database
migrations by leveraging AWS Snowball, AWS DataSync, and Amazon FSx. I
demonstrated how you can optimize a one-time full backup transfer to AWS
when there is a local network bandwidth constraint using an AWS
Snowball device. I also showed how you can transfer incremental backups
using AWS DataSync and Amazon FSx for Windows File Server, keeping your
SQL Server in AWS up to date until your application cutover. This
solution can help you automate and accelerate data transfer, freeing up
your on-premises storage capacity. By doing so, you can reduce your
organizational costs by moving that data off expensive storage systems.
Subscribe to:
Posts (Atom)